PNJ génératifs : les 5 obstacles qui ralentissent l’IA dans vos jeux
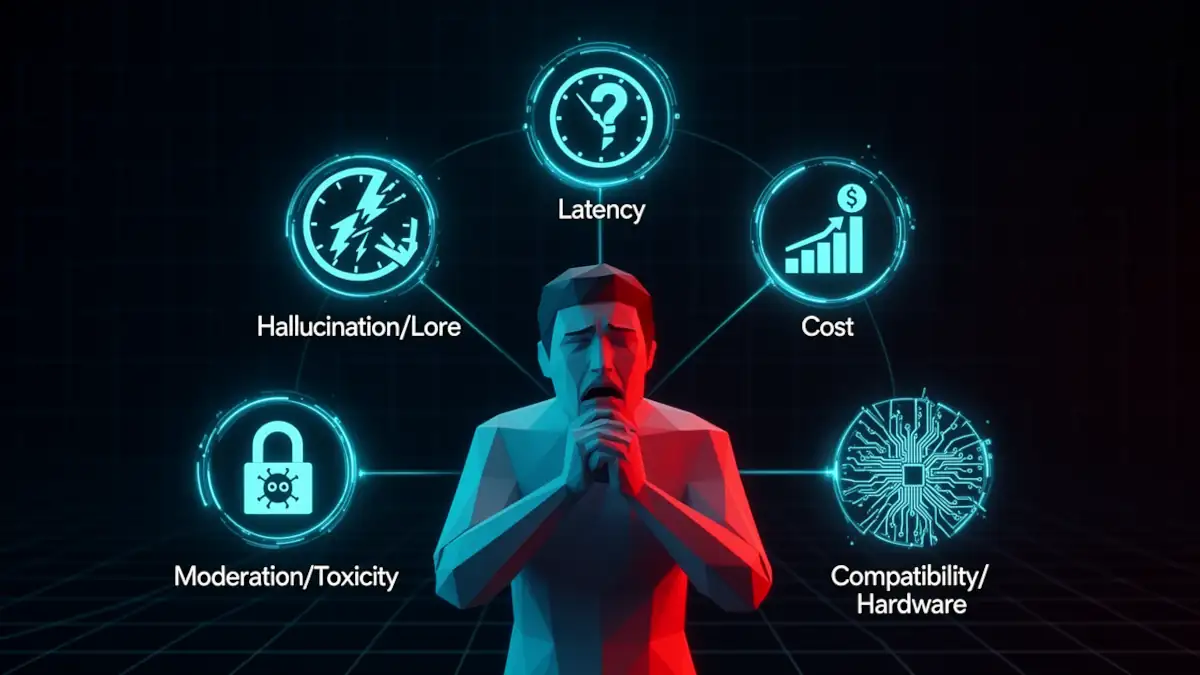
Le rêve du PNJ qui improvise, se souvient de vous et fait évoluer l’histoire est à portée de main. Pourtant, si l’IA générative est partout dans les studios, elle est presque absente de nos jeux. Pourquoi ? Parce que le passage d’une démo technique à un système stable, immersif et abordable à l’échelle d’un AAA soulève des défis majeurs que l’industrie n’a pas encore totalement résolus.
Les studios investissent massivement, mais seuls quelques titres expérimentaux (comme Vaudeville ou inZOI) intègrent des PNJ conversationnels libres. Voici les cinq obstacles qui ralentissent l’intégration des Intelligences Artificielles de nouvelle génération dans nos expériences de jeu.
1. La barrière critique de la latence (le facteur d’immersion)
Pour un joueur, une conversation ne doit pas s’interrompre plus de quelques secondes. Les PNJ génératifs doivent répondre en moins de 1 à 2 secondes pour que l’échange reste fluide et immersif.
- Le problème du cloud : Un LLM (Large Language Model) hébergé sur le cloud ajoute le temps de transmission aller-retour sur internet (latence réseau), ce qui brise systématiquement ce seuil critique.
- La solution locale : C’est pourquoi l’industrie se tourne vers l’IA locale. En utilisant des moteurs ultra-optimisés comme TensorRT-LLM ou vLLM directement sur la carte graphique (RTX 4000/5000), le temps de réponse peut être ramené à quelques centaines de millisecondes (environ 300 ms), rendant l’échange quasi instantané. L’obstacle ici est la nécessité pour le joueur de posséder un GPU puissant.
2. Le risque narratif de l’hallucination
C’est l’épée de Damoclès des PNJ. Un LLM a tendance à halluciner, c’est-à-dire à générer des informations qui semblent plausibles mais qui sont factuellement fausses.
Dans un jeu de rôle ou d’aventure, un PNJ doit être une source d’information fiable : il ne peut pas contredire le lore établi, révéler des spoilers ou se tromper sur la localisation d’une quête.
- La réponse des studios : Pour l’instant, les développeurs préfèrent des PNJ conversationnels très encadrés (avec des garde-fous stricts) ou se contentent d’IA génératives pour les dialogues secondaires ou le fluff narratif, où une erreur n’est pas critique pour la progression du jeu.
3. Le coût économique de l’inférence à grande échelle
Un LLM exécuté dans le cloud est facturé à l’usage (par token généré).
Imaginez un jeu multijoueur comme un MMO ou un Battle Royale avec des milliers de joueurs interagissant simultanément avec des PNJ génératifs. Ce coût, multiplié par des millions d’heures de jeu, devient astronomique et non viable pour un modèle économique classique (prix d’achat ou abonnement fixe).
L’IA locale résout partiellement ce problème pour l’utilisateur, mais le studio doit tout de même investir lourdement en recherche et développement pour compresser et optimiser ses modèles afin qu’ils tiennent sur nos cartes graphiques tout en restant performant.
4. Le cauchemar de la modération et de la toxicité
Lorsque l’on donne la parole à une IA capable d’improviser, on ouvre la boîte de Pandore. Un PNJ conversationnel doit respecter les lois, les valeurs du studio et, surtout, ne pas déraper dans la toxicité ou le discours de haine.
- Le problème de la modération : Contrôler des milliards d’échanges potentiels est extrêmement difficile. Si une IA se met à générer du contenu inapproprié, la réputation du studio est en jeu.
- La réglementation : Les systèmes d’IA doivent respecter des lois comme l’AI Act européen. Cela oblige les studios à intégrer de lourdes couches de filtrage et de modération, ce qui ajoute complexité et latence au processus de dialogue.
5. La compatibilité matérielle du parc utilisateur
Même si un joueur possède une RTX puissante, son voisin possède peut-être une GTX plus ancienne ou une carte AMD.
Un studio doit s’assurer que son jeu est accessible au plus grand nombre. Déployer un PNJ génératif performant qui ne fonctionne correctement que sur une RTX 5090 (ou une carte avec au moins 16 Go de VRAM) exclut une part majeure de son marché.
Les moteurs d’inférence universels comme vLLM (qui supporte mieux l’écosystème open-source et des alternatives comme ROCm d’AMD) sont cruciaux pour l’adoption, mais leur performance est parfois inférieure à celle des solutions propriétaires ultra-optimisées pour Nvidia (TensorRT-LLM). Le studio doit choisir entre une performance optimale pour l’élite ou une compatibilité maximale pour le grand public.
L’avenir : vers un compromis intelligent
Ces obstacles expliquent pourquoi la véritable révolution de l’IA dans nos jeux se concentre sur l’IA invisible (création d’assets, débuggage) plutôt que sur les PNJ.
Toutefois, les solutions sont en cours de déploiement : les puces dédiées à l’IA (Tensor Cores), la quantification (INT4, NVFP4) et les moteurs d’inférence de nouvelle génération rapprochent le rêve du PNJ intelligent. Il est probable que les futurs jeux AAA utiliseront une IA locale pour la réactivité, complétée par une IA cloud pour les mises à jour et les événements mondiaux complexes.
A lire également : IA Locale : Pourquoi votre RTX va transformer vos jeux
Pour ne rien rater, abonnez-vous à Cosmo Games sur Google News et suivez-nous sur X (ex Twitter) en particulier pour les bons plans en direct. Vos commentaires enrichissent nos articles, alors n'hésitez pas à réagir ! Un partage sur les réseaux nous aide énormément. Merci pour votre soutien !





