Les sociétés d’IA résistent à l’idée de respecter le droit d’auteur

Les entreprises spécialisées dans l’intelligence artificielle (IA) ont divers arguments contre le paiement de contenus protégés par le droit d’auteur. Les grandes entreprises leaders dans le domaine de l’IA ne montrent pas d’intérêt pour payer l’utilisation de matériel protégé par le droit d’auteur comme données d’entraînement. Nous abordons sur cette page les différentes raisons qu’elles avancent.
Les plus grandes entreprises en IA ne manifestent pas d’intérêt à rémunérer l’utilisation de matériel protégé par le droit d’auteur comme données d’entraînement. Pourtant les contenus de qualité sont des éléments essentiels pour les IA génératives comme ChatGPT, Bard ou encore les IA génératives d’image comme Midjourney, DALL-E et Stable Diffusion. Lorsque les IA génératives nous répondent, elles se basent souvent des contenus d’auteur, mais ces derniers n’en bénéficient pas. C’est à dire que les utilisateurs ne consultent pas leurs pages web, ce qui élimine toutes sources de revenus pour les auteurs. Pourtant les contenus de qualité, écrit par des humains, restent un élément essentiel au bon entrainement des différentes intelligence artificielles.
Le cas du New York Times contre ChatGPT
Parmi toutes les indications publiques suggérant que nous progressons encore plus profondément en territoire inconnu en ce qui concerne l’IA générative et le droit d’auteur, une éventuelle poursuite du New York Times contre OpenAI, le créateur de ChatGPT, se démarque particulièrement.
Selon les informations de NPR, le Times envisage de prendre des mesures judiciaires contre la société technologique après l’échec des négociations entre les deux organisations concernant un accord de licence. Cet accord aurait pu permettre à OpenAI d’accéder aux archives et aux reportages du journal contre une rémunération.
L’une des principales préoccupations soulevées par le Times est que OpenAI pourrait devenir un « concurrent direct du journal en générant du texte répondant aux questions à partir des reportages et des écrits originaux du personnel du journal« , comme le rapporte NPR, dont les journalistes ont interrogé plusieurs avocats du Times.
Lorsque OpenAI a publié sa fonctionnalité ChatGPT with Bing, il était même possible de retrouver des articles complets issus de différentes sources. OpenAI a alors désactivé la fonctionnalité ChatGPT de recherche Web avec Bing. Depuis la société a corrigé le problème et la fonctionnalité est à nouveau disponible.
Des actions en justice pour protéger le droit d’auteur contre les IA
L’action en justice du Times ne serait en aucun cas la première attaque légale dirigée contre OpenAI par des éditeurs. La société technologique est déjà confrontée à une action collective intentée par un groupe d’auteurs, dont la comédienne Sarah Silverman, pour avoir prétendument intégré des parties de leurs œuvres dans leurs outils d’IA, notamment dans la formation de leurs ensembles de données. Cependant, si le Times et OpenAI devaient entrer en conflit judiciaire, cela créerait un précédent important entre le monde de l’édition et le secteur des technologies de l’IA et des modèles de langage de grande envergure.

En effet, une éventuelle bataille juridique surviendrait à un moment où les soupçons à l’égard des activités d’OpenAI sont de plus en plus marqués, comme en témoigne un article de Vanity Fair détaillant les inquiétudes du Times concernant cette technologie émergente. « Ne mettez aucune information propriétaire, y compris des articles du Times publiés ou non publiés, dans des outils d’IA générative, tels que ChatGPT, Bing Chat, Bard, ou autres« , ont averti plusieurs rédacteurs en chef adjoints du New York Times dans un e-mail adressé à l’ensemble de la rédaction pendant l’été.
Ce mail interne illustre un autre problème. Lorsque nous utilisons ChatGPT, Bing Chat ou Bard, nous insérons souvent des textes dans nos questions, parfois de long contenu. Ces contenus peuvent être issus de données propriétaires, de matériels protégés par le droit d’auteur. Cela permet d’améliorer la qualité des réponses des IA génératrices, mais c’est aussi une manière pour les IA de s’améliorer en continue à partir des informations que nous fournissons. Ainsi chaque utilisateur contribue à l’amélioration continue des modèles d’intelligence artificielle. La confidentialité des échanges avec les IA génératrices devient ainsi un élément essentiel, que ce soit pour le droit d’auteur mais aussi pour l’utilisation de données sensibles. OpenAI a bien compris cette problématique, ce qui a amené la société à lancer un abonnement pour les entreprises ChatGPT Enterprise. Avec cet abonnement, la société précise « Les indications ou les données des clients ne sont pas utilisées pour former les modèles.« .
La position des sociétés d’IA génératrice sur le droit d’auteur
Le bureau du droit d’auteur des États-Unis sollicite des commentaires du public concernant de potentielles nouvelles règles liées à l’utilisation de matériel protégé par le droit d’auteur par l’IA générative. Les plus grandes entreprises en IA dans le monde ont exprimé leurs opinions à ce sujet. Vous trouverez ci-dessous les différents arguments présentés par Meta, Google, Microsoft, Adobe, Hugging Face, StabilityAI et Anthropic, ainsi qu’une réponse d’Apple qui se concentre sur le droit d’auteur du code généré par l’IA.
Bien qu’il y ait certaines variations dans leurs approches, l’idée générale est la même : elles estiment qu’elles ne devraient pas être tenues de payer pour l’entraînement de leurs modèles d’IA même avec des œuvres protégées par le droit d’auteur.
Les arguments des sociétés d’IA sur le respect du droit d’auteur
Le bureau du droit d’auteur a lancé une enquête le 30 août, avec une date limite pour les commentaires écrits fixée au 18 octobre. L’objectif est d’identifié les éventuelles modifications à apporter concernant l’utilisation de données protégées par le droit d’auteur pour l’entraînement de modèles d’IA, ainsi que la responsabilité du droit d’auteur en matière d’IA. La possibilité de protéger par le droit d’auteur des contenus générés par l’IA est également abordée.

La formation de l’IA est semblable à la lecture d’un livre. Si l’entraînement pouvait être effectué sans créer de copies, il n’y aurait pas de questions de droit d’auteur à considérer. En effet, l’acte d' »extraction de connaissances », pour reprendre la métaphore de la Cour dans l’affaire Harper & Row, tout comme la lecture d’un livre et l’acquisition des faits et des idées qu’il contient, ne serait pas seulement non contraignant, mais contribuerait également à l’objectif fondamental du droit d’auteur. Le simple fait que, d’un point de vue technologique, des copies doivent être faites pour extraire ces idées et ces faits à partir d’œuvres protégées par le droit d’auteur ne devrait pas altérer ce résultat.
META
Les titulaires de droits d’auteur ne percevraient de toute manière que peu d’argent. L’imposition d’un régime de licences inédit maintenant, bien après coup, causerait la confusion alors que les développeurs cherchent à identifier des millions et des millions de détenteurs de droits, pour un bénéfice très limité, étant donné que toute redevance équitable serait minime en raison de l’insignifiance de chaque œuvre parmi un ensemble de données pour l’IA.
Microsoft
Modifier le droit d’auteur pourrait nuire aux petits développeurs d’IA. Toute obligation d’obtenir un consentement pour l’utilisation d’œuvres accessibles à des fins d’entraînement découragerait l’innovation en IA. Il n’est pas praticable d’atteindre l’échelle de données nécessaire au développement de modèles d’IA responsables, même lorsque l’identité de l’œuvre et de son propriétaire est connue. De tels régimes de licence entraveraient également l’innovation des start-ups et des nouveaux entrants qui n’ont pas les ressources nécessaires pour obtenir des licences, laissant le développement de l’IA entre les mains d’un petit groupe d’entreprises disposant des moyens de mettre en place des programmes de licences à grande échelle ou de développeurs dans des pays ayant décidé que l’utilisation d’œuvres protégées par le droit d’auteur pour former des modèles d’IA ne constitue pas une violation.
Andreessen Horowitz
Les investisseurs ont dépensé « des milliards et des milliards ». Au cours de la dernière décennie ou plus, il y a eu une quantité énorme d’investissements, en milliards et en milliards de dollars, dans le développement de technologies liées à l’IA, en se basant sur la compréhension que, selon le droit d’auteur actuel, toute copie nécessaire pour extraire des données statistiques est permise. Un changement de régime entraînerait une perturbation significative des attentes établies dans ce domaine. Ces attentes ont été un facteur critique dans l’importante mobilisation de capitaux privés dans les entreprises d’IA basées aux États-Unis, ce qui a fait des États-Unis un leader mondial en matière d’IA. Saper ces attentes mettrait en péril les investissements futurs, ainsi que la compétitivité économique et la sécurité nationale des États-Unis.
Anthropic
La loi actuelle convient ; ne la modifiez pas. Une politique judicieuse a toujours reconnu la nécessité de limiter adéquatement le droit d’auteur pour favoriser la créativité, l’innovation et d’autres valeurs, et nous estimons que la législation existante et la collaboration continue entre toutes les parties prenantes peuvent concilier les intérêts variés en jeu, permettant ainsi de libérer les avantages de l’IA tout en traitant les préoccupations.
Adobe
C’est un usage équitable, tout comme lorsque Accolade a copié le code de Sega. Dans l’affaire Sega vs Accolade, la cour d’appel a statué que la copie intermédiaire du logiciel de Sega constituait un usage équitable. Le défendeur a réalisé des copies tout en effectuant de la rétro-ingénierie pour découvrir les exigences fonctionnelles, des informations non protégées, permettant de créer des jeux compatibles avec la console de jeu de Sega. Une telle copie intermédiaire a également bénéficié au public : elle a entraîné une augmentation du nombre de jeux vidéo conçus indépendamment (contenant à la fois des éléments fonctionnels et créatifs) disponibles pour la console de jeu de Sega. Cette croissance de l’expression créative était précisément ce que la loi sur le droit d’auteur visait à promouvoir.
Anthropic
La copie n’est qu’une étape intermédiaire. Pour Claude, comme mentionné précédemment, le processus d’entraînement effectue des copies d’informations dans le but d’effectuer une analyse statistique des données. La copie n’est qu’une étape intermédiaire, permettant d’extraire des éléments non protégés de l’ensemble des œuvres, afin de créer de nouvelles sorties. De cette manière, l’utilisation de l’œuvre protégée par le droit d’auteur originale n’est pas expressive, c’est-à-dire qu’elle ne réutilise pas l’expression protégée par le droit d’auteur pour la communiquer aux utilisateurs.
Hugging Face
L’entraînement sur du matériel protégé par le droit d’auteur relève de l’usage équitable. L’utilisation d’une œuvre donnée pour l’entraînement sert un objectif largement bénéfique : la création d’un modèle d’IA distinctif et productif. Plutôt que de remplacer l’expression communicative spécifique de l’œuvre initiale, le modèle est capable de créer une grande variété de sorties différentes totalement indépendantes de cette expression protégée par le droit d’auteur. Pour ces raisons, les modèles d’IA générative sont généralement considérés comme relevant de l’usage équitable lorsqu’ils s’entraînent sur de nombreuses œuvres protégées par le droit d’auteur. Nous utilisons délibérément le terme « généralement », car on peut imaginer des motifs de faits qui poseraient des questions plus complexes.
StabilityAI
Plusieurs juridictions, dont Singapour, le Japon, l’Union européenne, la République de Corée, Taïwan, la Malaisie et Israël, ont réformé leurs lois sur le droit d’auteur pour créer des zones de sécurité permettant l’entraînement de l’IA, obtenant ainsi des effets similaires à l’usage équitable. Au Royaume-Uni, le conseiller scientifique en chef du gouvernement a recommandé que « si l’objectif du gouvernement est de promouvoir une industrie de l’IA innovante au Royaume-Uni, il devrait permettre l’exploitation des données, du texte et des images disponibles (en entrée) et utiliser les protections existantes du droit d’auteur et de la propriété intellectuelle sur les résultats de l’IA en sortie« .
Apple
Laissez-nous protéger par le droit d’auteur le code généré par notre IA. Dans les circonstances où un développeur humain contrôle les éléments expressifs de la sortie et prend les décisions pour modifier, ajouter, améliorer, voire rejeter le code suggéré, le code final résultant des interactions du développeur avec les outils aura une suffisante paternité humaine pour être protégé par le droit d’auteur.

Analyse de l’enquête sur les questions de droits d’auteur concernant l’IA
Au-delà des positions des sociétés d’intelligence artificielle, l’enquête révèle différents points de vue, plus divergents. Nous avons analysé les commentaires dans leur globalité.
- Usage des données d’art humain : Il y a une inquiétude que l’IA utilise l’art humain ou autres contenus sans permission, ce qui est perçu comme un vol.
- Protection du droit d’auteur : Il existe un sentiment que les créations d’IA ne devraient pas bénéficier de la protection du droit d’auteur, ce qui implique que les contributions humaines seraient plus valorisées.
- Consentement et compensation : La question du consentement pour utiliser les œuvres d’art et autres contenus dans l’entraînement de l’IA et la compensation pour cet usage sont des sujets de préoccupation.
- Impact sur les créateurs : Les commentateurs soulignent l’impact négatif sur les créateurs lorsque leurs œuvres sont utilisées par l’IA, souvent sans reconnaissance ni rétribution.
Ces perspectives fournissent un aperçu des modifications potentielles qui pourraient être envisagées dans la réglementation du droit d’auteur concernant l’IA, notamment en termes de consentement, de rémunération et de reconnaissance des contributions artistiques humaines.
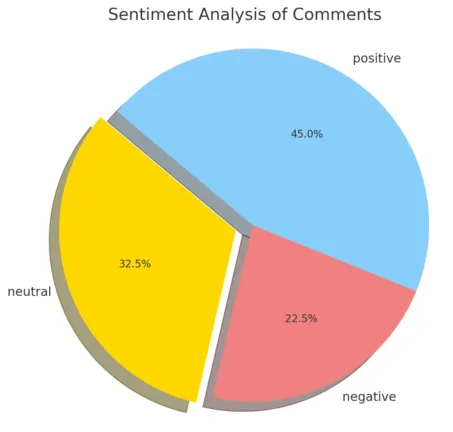
Analyse de sentiments des commentaires
Voici une représentation graphique de l’analyse des sentiments des commentaires sur l’IA et les droits d’auteur. Chaque portion du graphique en camembert représente la proportion de phrases exprimant un sentiment positif, négatif ou neutre.
IA : les sujets de préoccupations les plus fréquents
Les pourcentages sont calculés par rapport au nombre total de phrases analysées et indiquent la fréquence à laquelle chaque thème apparaît dans l’ensemble des commentaires. Par exemple, le thème « Créations IA » apparaît dans 77% des commentaires, indiquant que c’est un sujet fréquemment discuté dans les commentaires.
| Thème | Pourcentage de commentaires |
|---|---|
| Créations IA | 77,07 % |
| Contribution Humaine | 41,47 % |
| Protection du Droit d’Auteur | 33,19 % |
| Utilisation Non Autorisée/Vol | 10,95 % |
| Consentement et Compensation | 9,83 % |
| Impact sur les Artistes | 3,79 % |
Les avis sur les questions de droits d’auteur, consentement et compensation

Les commentaires analysés reflètent une préoccupation significative concernant le consentement et la compensation lors de l’utilisation d’œuvres d’art et d’autres contenus pour l’entraînement de l’intelligence artificielle. Voici un résumé des points de vue exprimés :
- Manque de consentement : Les commentateurs soulignent le fait que les œuvres sont souvent utilisées sans l’accord explicite des créateurs. Cela est perçu comme un manque de respect pour les droits d’auteur et de propriété intellectuelle des artistes, créateurs ou rédacteurs.
- Compensation insuffisante : Il y a une insatisfaction évidente parmi les contributeurs que les artistes et créateurs ne reçoivent pas de compensation équitable lorsque leurs œuvres sont utilisées pour entraîner des modèles d’IA. Cela est souvent considéré comme injuste, surtout lorsque les entités utilisant ces données peuvent bénéficier économiquement de l’IA.
- Reconnaissance des contributions : Les artistes et créateurs souhaitent être reconnus pour leur travail. La reconnaissance va au-delà de la compensation financière et englobe le crédit pour la création, qui est souvent omis lorsque les œuvres sont intégrées dans de grands ensembles de données.
- Conséquences pour les créateurs : Les commentateurs expriment des inquiétudes quant aux effets négatifs sur les créateurs, allant de la dévalorisation de leur travail à la perte potentielle de revenus et d’opportunités, car les œuvres d’art et autres contenus peuvent être reproduites et utilisées sans leur participation active.
- Appels à la régulation : Les commentaires appellent à des réglementations plus strictes pour protéger les droits d’auteur, y compris des mécanismes clairs pour le consentement et des structures de compensation adéquates qui garantissent que les créateurs sont équitablement rémunérés pour l’utilisation de leurs œuvres.
Ces opinions mettent en évidence un besoin de considérer attentivement les droits d’auteur dans l’écosystème de l’IA et de développer des pratiques éthiques et légales qui soutiennent à la fois l’innovation et la justice pour ceux dont les travaux contribuent à la technologie.
N’hésitez pas à réagir à ces déclarations sur la gestion des droits d’auteur par les IA génératrices à l’aide des commentaires. Nous utiliserons vos avis pour enrichir cette page.
A lire aussi
Pour ne rien rater, abonnez-vous à Cosmo Games sur Google News et suivez-nous sur X (ex Twitter) en particulier pour les bons plans en direct. Vos commentaires enrichissent nos articles, alors n'hésitez pas à réagir ! Un partage sur les réseaux nous aide énormément. Merci pour votre soutien !