Guide de prompting LTX 2.3 : les méthodes qui fonctionnent vraiment
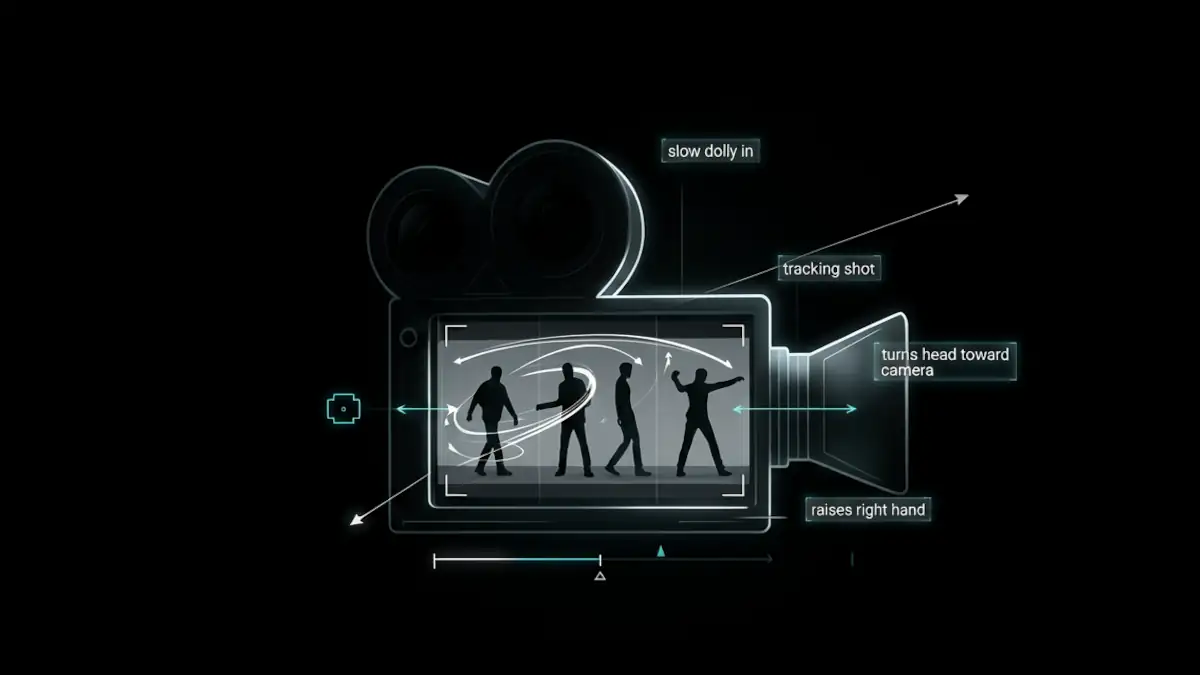
LTX 2.3 est capable de produire des vidéos impressionnantes en local, mais il se montre également beaucoup plus exigeant que la plupart des générateurs d’images. De nombreux utilisateurs découvrent rapidement que les prompts qui fonctionnent parfaitement avec Flux ou SDXL produisent parfois des mouvements incohérents, des personnages instables ou des scènes difficiles à contrôler.
Après plusieurs mois de tests réalisés, de nombreuses vidéos et d’échange avec la communauté et les utilisateurs avancés de ComfyUI, plusieurs bonnes pratiques se dégagent clairement. Ce guide rassemble les techniques les plus efficaces pour améliorer la cohérence des mouvements, préserver l’identité des personnages et obtenir un meilleur contrôle sur vos générations vidéo.
Pourquoi LTX 2.3 est différent des générateurs d’images
La plupart des utilisateurs découvrent LTX 2.3 après avoir utilisé des générateurs d’images comme Flux, SDXL, Midjourney ou d’autres. C’est souvent à ce moment qu’apparaît une première source de frustration : un prompt capable de produire une image exceptionnelle ne génère pas forcément une bonne vidéo. Si vous débutez avec l’écosystème ComfyUI, je vous invite à consulter également notre guide des meilleures ressources ComfyUI pour trouver des bases de travail fiable, sans réinventer la roue.
Pour revenir à la question de base, pourquoi LTX 2.3 est différent ? La raison est simple. Une image doit être cohérente à un instant donné. Une vidéo doit rester cohérente pendant toute sa durée. Le prompt doit tenir compte de l’espace temps.
Lorsque vous demandez à un modèle d’image de générer un personnage, il lui suffit de produire un seul visage crédible. Avec un modèle vidéo, ce même visage doit conserver :
- ses proportions ;
- ses expressions ;
- son éclairage ;
- sa coiffure ;
- ses vêtements ;
pendant plusieurs dizaines ou centaines de frames.
Le défi est encore plus complexe lorsqu’un mouvement est impliqué. Le modèle doit alors gérer simultanément :
- le sujet ;
- son animation ;
- les mouvements de caméra ;
- les interactions avec l’environnement ;
- la cohérence temporelle de l’ensemble.
C’est précisément pour cette raison que les prompts très populaires dans le monde de l’image fonctionnent souvent mal avec LTX 2.3.
Par exemple :
epic cinematic masterpiece
stunning
award-winning
beautiful composition
ultra detailedCes termes peuvent légèrement influencer l’esthétique générale, mais ils n’apportent pratiquement aucune information exploitable concernant le mouvement.
À l’inverse, un prompt comme :
slow dolly in
turns head toward camera
raises right hand
tracking shot
walks forwarddécrit des actions concrètes et des mouvements précis que le modèle peut comprendre et traduire beaucoup plus facilement en animation.
C’est pourquoi les meilleurs prompts LTX ressemblent souvent davantage à des indications de tournage qu’à des prompts artistiques traditionnels.
Avant même de parler d’optimisation, il faut donc adopter un changement de mentalité :
Avec LTX 2.3, vous ne décrivez pas seulement une image. Vous décrivez une scène qui doit évoluer dans le temps.
Cette différence fondamentale explique la majorité des problèmes rencontrés par les débutants.
Règle n°1 : décrire la physique, pas l’émotion
L’une des erreurs les plus fréquentes consiste à utiliser des adjectifs émotionnels ou des concepts abstraits en espérant que le modèle comprenne automatiquement leur traduction visuelle.
Par exemple :
A furious mansemble parfaitement clair pour un humain. Pourtant, cette instruction laisse une énorme liberté d’interprétation au modèle.
À quoi ressemble exactement la colère ?
- Une mâchoire crispée ?
- Des sourcils froncés ?
- Une respiration rapide ?
- Un regard fixe ?
- Des gestes brusques ?
Le modèle doit deviner.
Or plus il doit interpréter, plus le risque de dérive augmente, plus vos itérations seront nombreuses.
Dans mes tests, ainsi que dans de nombreux retours de la communauté, les résultats deviennent généralement plus stables lorsque l’émotion est remplacée par ses manifestations physiques.
Exemple
Prompt abstrait :
A furious man shouting.Prompt plus efficace :
A man with a tightened jaw, furrowed brows,
wide-open mouth, visible neck tension,
heavy breathing.Le second prompt donne au modèle des éléments concrets à animer plutôt qu’un concept à interpréter.
Le même principe s’applique à pratiquement toutes les émotions.
| Émotion | Description physique |
|---|---|
| Tristesse | Head lowered, slow blinking, slumped shoulders |
| Colère | Tightened jaw, narrowed eyes, tense posture |
| Peur | Wide eyes, rapid breathing, trembling hands |
| Joie | Slight smile, relaxed posture, raised cheeks |
Plus votre description est physique et observable, plus LTX 2.3 dispose d’informations exploitables pour générer une animation cohérente.
Cette logique constitue probablement le changement le plus important à adopter lorsqu’on passe d’un générateur d’images à un générateur vidéo.
Règle n°2 : la caméra est souvent plus importante que le style
Lorsque l’on débute avec LTX 2.3, il est tentant d’empiler les adjectifs artistiques dans l’espoir d’améliorer le rendu :
epic
cinematic
beautiful
masterpiece
stunning
award-winningCe type de vocabulaire est omniprésent dans les prompts destinés aux générateurs d’images. Pourtant, dans un contexte vidéo, son impact est souvent limité.
Les retours de la communauté ainsi que les nombreux tests réalisés sur LTX 2.3 montrent qu’un langage inspiré du cinéma produit généralement des résultats plus prévisibles.
Pourquoi ?
Parce que ces termes décrivent directement le comportement de la caméra ou la manière dont la scène doit évoluer dans le temps.
Les mots qui apportent réellement de l’information
Au lieu d’écrire :
A beautiful cinematic portrait of a woman.Essayez :
Medium close-up shot,
slow dolly in,
soft side lighting,
shallow depth of field.Le second prompt fournit plusieurs informations exploitables :
- type de cadrage ;
- mouvement de caméra ;
- éclairage ;
- profondeur de champ.
Le modèle dispose alors d’indications beaucoup plus précises pour construire la séquence.
Quelques termes particulièrement utiles
Valeurs de plan
close-up
medium close-up
medium shot
wide shot
extreme close-upMouvements de caméra
slow dolly in
slow dolly out
tracking shot
handheld camera
push in
pull backGestion de la profondeur
shallow depth of field
deep focus
background blur
foreground blurÉclairage
soft daylight
rim lighting
side lighting
overhead lighting
ambient neon glowComparaison pratique
Prompt orienté style :
A stunning cinematic futuristic soldier,
epic atmosphere,
masterpiece,
ultra detailed.Prompt orienté caméra :
Medium close-up shot of a futuristic soldier,
slow dolly out,
soft rim lighting,
shallow depth of field,
post-apocalyptic street background.Dans la pratique, le second prompt offre généralement un meilleur contrôle sur le résultat final.
L’objectif n’est pas de bannir complètement les termes artistiques. Ils peuvent contribuer à l’ambiance générale de la scène.
En revanche, lorsqu’un arbitrage est nécessaire, il est souvent préférable de consacrer ses tokens à des informations de cadrage, de mouvement et d’éclairage plutôt qu’à une accumulation d’adjectifs esthétiques.
Règle n°3 : décomposer les mouvements en micro-actions
Une autre erreur fréquente consiste à demander au modèle une action complexe sans lui fournir suffisamment d’informations sur sa mécanique.
Prenons l’exemple suivant :
A woman dances energetically.Pour un humain, la scène paraît simple.
Pour le modèle, elle est extrêmement ambiguë.
Danser peut signifier :
- tourner sur soi-même ;
- lever les bras ;
- sauter ;
- avancer ;
- reculer ;
- effectuer une chorégraphie complète.
Le modèle doit alors inventer lui-même une grande partie du mouvement.
C’est souvent dans ce type de situation que l’on observe :
- des bras qui se déforment ;
- des jambes instables ;
- des mouvements incohérents ;
- du morphing.
La méthode des micro-actions
Les utilisateurs expérimentés obtiennent généralement de meilleurs résultats en découpant les actions complexes en mouvements simples.
Au lieu de :
A woman dances energetically.Utilisez :
A woman raises her right arm,
rotates her shoulders,
takes one step forward,
slight smile,
smooth body movement.Le modèle reçoit alors une série d’instructions beaucoup plus faciles à interpréter.
Pourquoi cela fonctionne mieux ?
Chaque action possède :
- un point de départ ;
- une direction ;
- un résultat attendu.
LTX 2.3 a beaucoup moins d’éléments à deviner.
Cette approche améliore souvent :
- la stabilité des membres ;
- la fluidité générale ;
- la cohérence temporelle ;
- la fidélité au prompt.
Pour les vidéos de dance, je vous conseille néanmoins d’utiliser des vidéos de références, fichiers OpenPose ou des squelettes de pose (notamment avec ControlNet ou OpenPose).
Les actions particulièrement difficiles
Certaines situations restent complexes pour la plupart des modèles vidéo actuels :
two people fighting
crowd running
complex choreography
wrestling
group dancingMême avec un bon prompt, ces scènes nécessitent souvent :
- plusieurs essais ;
- plusieurs seeds ;
- parfois du montage en post-production.
Lorsque cela est possible, il est souvent plus efficace de simplifier l’action et de faire un montage rapide (avec des plans courts et dynamiques), plutôt que de demander directement une scène très complexe.
Une règle simple peut servir de référence :
Plus le mouvement est important, plus il doit être décrit précisément.
Règle n°4 : préserver l’identité du personnage entre plusieurs plans
L’un des plus grands défis de la vidéo IA consiste à maintenir un personnage cohérent tout au long d’une séquence.
Même lorsque chaque plan paraît correct individuellement, il n’est pas rare d’observer :
- une couleur de cheveux qui change ;
- des vêtements légèrement différents ;
- un visage qui évolue progressivement ;
- des proportions qui dérivent ;
- un éclairage qui modifie fortement l’apparence du sujet.
Ces problèmes sont particulièrement visibles lorsque plusieurs générations sont assemblées dans un même montage.
Pourquoi l’identité dérive-t-elle ?
Contrairement à un tournage réel, LTX 2.3 ne possède aucune notion intrinsèque de personnage. À chaque génération, le modèle tente simplement de reconstruire ce que votre prompt décrit. L’idéal est d’utiliser une image de référence avec le personnage.
Sans image de référence, si certaines informations changent ou disparaissent, même légèrement, il peut interpréter qu’il s’agit d’une nouvelle personne.
Les éléments à verrouiller
Pour améliorer la cohérence entre plusieurs plans, essayez de conserver systématiquement :
- la même coiffure ;
- les mêmes vêtements ;
- les mêmes couleurs ;
- le même type d’éclairage ;
- la même focale ;
- les mêmes caractéristiques faciales.
Par exemple :
Short brown buzzcut,
dark leather jacket,
35mm lens,
soft daylight,
light beard.Réutiliser exactement ces éléments d’un plan à l’autre produit souvent de meilleurs résultats que de reformuler à chaque génération. Toutefois sans image de référence, l’identité du personnage sera quasi impossible à conserver.
L’importance du cadrage
Un changement brutal de cadrage dans un même plan augmente le risque de dérive.
Par exemple :
Wide shotpuis :
Extreme close-upLorsque cela est possible, faites évoluer progressivement les plans :
Wide shot
→ Medium shot
→ Medium close-up
→ Close-upCette approche facilite généralement la qualité des mouvements de caméra et limite la créativité du modèle.
Les workflows spécialisés
Si vous utilisez ComfyUI, de nombreux workflows avancés reposent sur :
- des images de référence (Image To Vidéo, I2V);
- des systèmes d’injection d’identité (IC LoRA, ID LoRA);
- des contrôles de pose, Depth, Canny (ControlNet).
- … et d’autres Workflow (Repaint, InPaint, Outpaint… )
Règle n°5 : supprimer les mots inutiles grâce au « Prompt Compression »
Une erreur fréquente consiste à penser qu’un prompt plus long produit automatiquement une meilleure vidéo. Dans la pratique, ce n’est pas toujours le cas.
LTX 2.3 doit interpréter chaque mot présent dans votre prompt. Lorsque celui-ci contient trop d’informations secondaires, les éléments réellement importants peuvent perdre en visibilité.
Exemple de prompt surchargé
A beautiful young man sitting peacefully on a wooden bench
during a wonderful summer afternoon while looking at the camera
with a very happy expression and amazing cinematic lighting.Le prompt fonctionne.
Mais une grande partie du texte n’apporte aucune information essentielle.
Version compressée
Young man,
wooden bench,
looking at camera,
slight smile,
soft daylight.Dans de nombreux cas, cette seconde version donnera un résultat tout aussi bon, voire meilleur.
Ce qu’il faut conserver
Privilégiez les informations qui influencent directement :
- le sujet ;
- l’action ;
- la caméra ;
- l’éclairage ;
- l’environnement.
- l’audio
Ce qui peut souvent être supprimé
Évitez d’accumuler :
beautiful
stunning
amazing
masterpiece
epic
award-winning
incredibleCes termes ne sont pas forcément inutiles, mais ils ont souvent moins d’impact qu’une instruction concrète concernant le mouvement ou la caméra. L’objectif n’est pas de créer le prompt le plus court possible. L’objectif est de supprimer tout ce qui ne contribue pas directement au résultat recherché et risque d’introduire du bruit.
Règle n°6 : utiliser les timecodes avec discernement
Les timecodes sont probablement l’une des techniques les plus discutées au sein de la communauté LTX. Contrairement à certaines idées reçues, cette méthode n’est pas documentée officiellement dans la documentation de Lightricks.
Cependant lors de mes tests et de nombreux retours d’expérience d’utilisateurs, les timecodes dans le prompt apportent des améliorations lorsqu’ils utilisent des repères temporels simples dans leurs prompts.
Exemple
[00:00] A man sitting at a desk.
[00:02] He slowly turns his head left.
[00:04] He raises his hand to his chin.L’objectif n’est pas de demander au modèle d’exécuter une action exactement à une frame précise. Les timecodes semblent plutôt agir comme des indicateurs de progression logique. Ils indiquent plus une évolution, qu’un temps précis. Par exemple, un prompt avec un timecode supérieur à la durée du plan sera quand même compris et bien interprêté par LTX 2.3. Bien sûr à condition que les dialogues puissent tenir sur le temps imparti.
Quand cette technique est utile
Elle peut être intéressante lorsque :
- plusieurs actions doivent s’enchaîner ;
- la scène comporte plusieurs mouvements distincts ;
- le modèle a tendance à figer l’animation.
- le modèle en génére pas les sons, dialogues et bruitages dans le bon ordre.
Quand elle apporte peu de bénéfices
Pour des scènes simples :
Woman walking forward.ou :
Man talking to camera.Dans ce cas, les timecodes sont souvent inutiles.
Une heuristique, pas une règle absolue
Il est important de considérer cette technique comme une astuce empirique. Dans certains workflows, elle améliore clairement les résultats. Dans d’autres, l’effet est faible voire imperceptible.
Comme souvent avec la vidéo IA, le meilleur moyen de trancher reste de tester plusieurs variantes sur une même scène.
Pour suivre les évolutions de LTX 2.3 et les recommandations officielles, consultez régulièrement :
- Documentation officielle
- GitHub officiel
- Modèle officiel sur Hugging Face
La section suivante aborde un autre sujet qui fait souvent débat dans la communauté : le Prompt Enhancer.
Règle n°7 : maîtriser le Prompt Enhancer au lieu de le subir
Les Workflow LTX 2.3 sont souvent distribués avec un système d’amélioration automatique des prompts. Dans l’écosystème ComfyUI, ce mécanisme prend généralement la forme du node TextGenerateLTX2Prompt ou d’un module équivalent intégré à certains workflows.
Son objectif est simple : transformer une idée courte en un prompt plus détaillé et adapté à LTX 2.3.
Par exemple :
Woman walking in a city.peut devenir :
A young woman confidently walking through a futuristic neon-lit city street at sunset, cinematic atmosphere, reflective wet pavement, vibrant colors, detailed architecture...Sur le papier, cela semble utile. Dans la pratique, les résultats sont plus nuancés.
Pourquoi le Prompt Enhancer peut poser problème
Lors de mes itérations et celle d’autres utilisateurs, l’otpimiseur de prompt introduit parfois :
- des objets non demandés ;
- des détails de décor parasites ;
- des modifications d’éclairage ;
- des changements de cadrage ;
- des mouvements de caméra inattendus.
Autrement dit, le système peut améliorer un prompt trop vague, mais il peut également dégrader un prompt déjà bien construit.
Quand l’utiliser
Le Prompt Enhancer reste pertinent dans plusieurs situations :
| Situation | Utilisation recommandée |
|---|---|
| Découverte du modèle | Oui |
| Recherche d’idées | Oui |
| Exploration créative | Oui |
| Tests rapides | Oui |
Si vous partez d’un concept simple et que vous cherchez de l’inspiration, il peut produire des résultats intéressants.
Quand le désactiver
À l’inverse, il est souvent préférable de le désactiver lorsque :
| Situation | Utilisation recommandée |
|---|---|
| Production vidéo sérieuse | Non |
| Contrôle précis de la caméra | Non |
| Workflow I2V | Non |
| Workflow A2V | Non |
| Shot-by-shot | Non |
Plus votre besoin de contrôle augmente, plus l’intérêt du Prompt Enhancer diminue.
Une bonne pratique simple
Lorsque vous développez une nouvelle scène :
- Testez éventuellement quelques idées avec le Prompt Enhancer.
- Sélectionnez la version qui vous intéresse.
- Réécrivez ensuite manuellement le prompt final.
- Désactivez l’enrichisseur pour la production.
Cette approche combine généralement le meilleur des deux mondes :
- créativité lors de la phase d’exploration ;
- contrôle lors de la phase de production.
Comprendre les workflows T2V, I2V et A2V
L’une des erreurs les plus fréquentes consiste à utiliser exactement le même type de prompt quel que soit le workflow.
Pourtant, le rôle du texte change radicalement selon que vous travaillez en :
- Text-to-Video (T2V) ;
- Image-to-Video (I2V) ;
- Audio-to-Video (A2V).
Vue d’ensemble
| Workflow | Rôle principal du prompt |
|---|---|
| T2V | Décrire l’ensemble de la scène |
| I2V | Décrire principalement le changement |
| A2V | Décrire l’ensemble de la scène sauf l’audio |
Comprendre cette différence améliore souvent davantage les résultats que l’ajout de nouveaux mots-clés.
Text-to-Video : le prompt construit toute la scène
En T2V, le modèle ne dispose d’aucune référence externe.
Le prompt doit donc fournir :
- le sujet ;
- l’environnement ;
- l’action ;
- la caméra ;
- l’éclairage.
Exemple :
Medium close-up shot of a cyberpunk engineer,
slow dolly in,
working on a holographic interface,
soft blue neon lighting,
shallow depth of field.Ici, chaque élément contribue directement à la construction de la scène.
Je vous conseille d’éviter le Text-to-Video, privilégier le Image-to-Video. En travaillant votre image avec des modèles d’image (FLUX, Z-Image, Qwen …)
Image-to-Video : le prompt complète l’image
Avec l’I2V, la situation change complètement.
Le modèle dispose déjà :
- du personnage ;
- du décor ;
- de la composition ;
- des couleurs.
Le texte n’a donc plus besoin de recréer ces informations.
C’est probablement la règle la plus importante à retenir :
Le prompt doit compléter l’image, pas la remplacer.
Exemple d’erreur classique
Image :
- femme assise dans un café.
Prompt :
A woman with brown hair sitting in a coffee shop,
wooden table,
warm lighting,
coffee cup.Le modèle connaît déjà ces informations. Les répéter inutilement peut créer des conflits ou favoriser des dérives visuelles.
Meilleure approche
The woman slowly lifts the cup,
looks toward the window,
camera tracking shot,
background remains static.Ici, le prompt décrit uniquement ce qui doit évoluer.
Cette approche améliore souvent :
- la stabilité du personnage ;
- la cohérence du décor ;
- le respect de l’image source.
Audio-to-Video : laisser l’audio piloter l’animation
L’A2V est probablement l’un des workflows les plus sous-estimés de LTX 2.3. De nombreux utilisateurs tentent encore de piloter des dialogues uniquement par le texte. Pourtant, lorsqu’une piste audio de qualité est disponible, elle constitue généralement un meilleur guide pour :
- les lèvres ;
- la mâchoire ;
- les micro-expressions ;
- le rythme du visage.
La stratégie la plus efficace consiste souvent à inverser le pipeline habituel.
- Générer l’audio en premier.
- Utiliser une même voix TTS sur toutes les scènes.
- Injecter cette piste dans le workflow A2V.
- Utiliser le prompt uniquement pour le cadrage et l’ambiance.
Exemple :
Close-up shot,
natural facial movement,
soft daylight,
35mm lens,
interview framing.Dans ce cas, l’audio pilote l’animation faciale tandis que le prompt contrôle la mise en scène.
Une piste audio avec les dialogues aide à piloter l’émotion et expressions faciales du personnage. L’idéal est de l’utiliser conjointement avec une image de référence. L’image dicte l’aspect du personnage. La piste audio, le dialogue (et bruitage si besoin). Il est également possible d’ajouter un ControlNet (Depth, Canny, Pose).
La section suivante rassemble plusieurs exemples complets de prompts T2V, I2V et A2V que vous pourrez utiliser comme base de travail.
Exemples de prompts efficaces pour LTX 2.3
Maintenant que nous avons vu les principes fondamentaux, examinons plusieurs exemples concrets.
L’objectif n’est pas de copier ces prompts mot pour mot, mais de comprendre leur structure afin de construire vos propres variantes.
Exemple Text-to-Video (T2V)
Dans un workflow T2V, le prompt doit fournir toutes les informations nécessaires à la construction de la scène.
Prompt
Medium close-up shot of a female android technician,
inside a futuristic repair workshop,
slow dolly in,
she turns her head toward the camera,
raises her right hand toward a holographic display,
soft blue neon lighting,
shallow depth of field,
clean background,
realistic motion.Pourquoi ce prompt fonctionne
- sujet clairement identifié ;
- environnement simple ;
- mouvement précis ;
- caméra explicite ;
- éclairage défini ;
- peu d’ambiguïtés.
Le modèle n’a pratiquement rien à deviner.
Exemple Image-to-Video (I2V)
Supposons que votre image source représente :
- une femme assise sur un banc ;
- parc urbain ;
- lumière de fin d’après-midi.
L’erreur classique consiste à réécrire toute la scène.
Mauvais exemple
A woman sitting on a bench in a park,
brown hair,
autumn atmosphere,
warm sunlight,
trees in background.La majorité de ces informations est déjà présente dans l’image.
Meilleur exemple
The woman slowly turns her head,
looks toward the camera,
slight smile,
gentle wind movement in her hair,
slow push in.Le prompt complète l’image au lieu de la combattre.
Exemple Audio-to-Video (A2V)
Dans un workflow A2V, l’audio pilote déjà une grande partie de l’animation faciale. Le prompt doit principalement gérer la mise en scène.
Prompt
Close-up interview shot,
natural facial motion,
soft daylight,
35mm lens,
stable camera,
professional documentary style.L’animation des lèvres et du visage sera principalement guidée par l’audio plutôt que par le texte.
Exemple utilisant les timecodes
Pour certaines scènes plus complexes, les timecodes peuvent servir de guide supplémentaire.
[00:00] A man sitting at a desk.
[00:02] He turns his head toward the monitor.
[00:04] He reaches for a coffee mug.
[00:06] He takes a sip.
Slow camera push in.Encore une fois, cette technique reste empirique. Elle ne garantit pas que chaque action se produira exactement au moment indiqué, mais elle peut aider à structurer la progression de la scène.
Les erreurs les plus fréquentes avec LTX 2.3
Après plusieurs mois de tests, certaines erreurs reviennent systématiquement.
Utiliser trop d’adjectifs
Mauvais :
Epic cinematic masterpiece,
beautiful,
stunning,
award-winning,
incredible atmosphere.Meilleur :
Medium shot,
slow tracking shot,
soft daylight,
shallow depth of field.Les termes techniques apportent généralement davantage d’informations exploitables.
Créer des arrière-plans trop complexes
Les scènes suivantes restent difficiles pour la plupart des modèles vidéo :
- rues bondées ;
- foules en mouvement ;
- dizaines de personnages ;
- décors extrêmement détaillés.
Dans la pratique, un environnement plus simple permet souvent d’obtenir :
- un sujet plus stable ;
- moins de morphing ;
- une meilleure cohérence temporelle.
Décrire plusieurs actions simultanément
Exemple difficile :
A man runs,
waves,
looks behind him,
avoids obstacles,
talks to another character.Chaque action supplémentaire augmente la complexité de la scène. Lorsque cela est possible, décomposez la séquence en plusieurs plans. N’oubliez pas qu’un générateur IA de vidéo comme LTX 2.3 est avant tout un générateur de plans. Ne lui demandez pas d’être un outil de montage.
La phase de montage dans DaVinci Resolve, Premiere ou autre est une étape obligatoire pour des vidéos de qualité. Cette phase vous permettra de rendre vos vidéos plus dynamiques, d’estomper les défauts et de capter l’attention.
Utiliser exactement le même prompt pour T2V et I2V
C’est l’une des erreurs les plus courantes.
- En T2V : le prompt crée la scène.
- En I2V : le prompt accompagne la scène.
Cette distinction est essentielle.
Ignorer la résolution cible
On observe généralement de meilleurs résultats lorsque la génération est réalisée directement dans un format proche de la résolution cible.
Les solutions IA d’Upscaling et d’interpolation (augmentation du nombre d’image par seconde) sont interessantes, tant que votre vidéo de base à une résolution et un framerate suffisant. Mais c’est un sujet qui mérite un article dédié.
Négliger les contraintes matérielles
Certains problèmes attribués au prompting proviennent en réalité :
- de mauvais paramètres de génération.
- d’une mauvaise combinaison de LoRA
- d’un manque de VRAM ;
- d’un format de modèle inadapté (ex: modèles GGUF avec quantification trop basse);
- d’un offloading excessif ;
Ces sujets sont détaillés dans nos guides « Quellle taille de modèle choisir en fonction de votre VRAM » et « Quel format choisir entre BF16, FP 16, FP8 et GGUF«
Dans la plupart des cas, un prompt simple, cohérent et adapté au workflow utilisé produit de meilleurs résultats qu’un prompt extrêmement long et complexe.
FAQ : les questions les plus fréquentes sur le prompting LTX 2.3
Pourquoi LTX 2.3 semble-t-il ignorer mon prompt ?
Dans la majorité des cas, le problème ne vient pas du modèle lui-même.
Les causes les plus fréquentes sont :
- un prompt trop abstrait ;
- trop d’adjectifs décoratifs ;
- plusieurs actions contradictoires ;
- un Prompt Enhancer qui modifie vos instructions ;
- un workflow I2V où le texte entre en conflit avec l’image source ;
- Idem pour les Worflow ControlNet (Pose, Canny, Depth …)
Avant d’ajouter davantage de détails, essayez souvent l’inverse : simplifiez votre prompt.
Les prompts négatifs fonctionnent-ils vraiment ?
Oui, mais leur efficacité dépend fortement du workflow utilisé.
Selon les configurations :
- certains workflows prennent correctement en compte les prompts négatifs ;
- d’autres utilisent des versions distillées où leur impact peut être réduit ;
- certains utilisateurs préfèrent utiliser des solutions comme NAG LTX pour renforcer le contrôle négatif.
Si vos prompts négatifs semblent ignorés, vérifiez d’abord votre workflow avant de modifier votre texte.
Faut-il utiliser le Prompt Enhancer ?
Le Prompt Enhancer est utile lorsque vous cherchez :
- des idées ;
- de l’inspiration ;
- des variantes créatives.
En revanche, lorsqu’un contrôle précis est nécessaire, la plupart des utilisateurs expérimentés préfèrent le désactiver.
Plus votre workflow est complexe, moins l’enrichissement automatique est généralement utile.
Quelle est la meilleure longueur de prompt ?
Il n’existe pas de nombre magique.
Cependant, l’expérience montre qu’un prompt court mais précis produit souvent de meilleurs résultats qu’un long paragraphe rempli d’adjectifs.
Une bonne question à se poser :
Chaque mot apporte-t-il réellement une information utile au mouvement, à la caméra ou à la scène ?
Si la réponse est non, il peut probablement être supprimé.
Les timecodes sont-ils officiellement supportés ?
À l’heure actuelle, la documentation officielle de LTX ne décrit pas les timecodes comme une fonctionnalité spécifique. Cependant, de nombreux utilisateurs rapportent des résultats intéressants lorsqu’ils les utilisent comme repères chronologiques. Ce que je confirme également avec mes nombreuses itérations. Ils doivent donc être considérés comme une technique expérimentale plutôt qu’une fonctionnalité garantie.
Comment obtenir des mouvements plus rapides ?
Les termes génériques comme :
quickly
fast
energeticproduisent souvent des résultats variables.
Dans la pratique, il est généralement préférable de :
- décrire des mouvements précis ;
- utiliser un vocabulaire de caméra adapté ;
- découper les actions complexes en plusieurs micro-actions.
- Au lieu d’un long plan, préférez des plans courts et un montage dynamique
Pourquoi mes personnages changent-ils d’apparence ?
Ce problème est extrêmement courant.
Pour réduire le risque de dérive :
- utilisez une image de référence lorsque cela est possible ;
Quelle résolution utiliser ?
Les recommandations évoluent régulièrement avec les nouvelles versions du modèle.
D’une manière générale :
- évitez les résolutions exotiques ;
- conservez un ratio cohérent ;
- effectuez l’upscale en post-production lorsque nécessaire.
Les ressources officielles restent la meilleure source d’information sur ce sujet :
- Documentation officielle : https://docs.ltx.video/
- GitHub officiel : https://github.com/Lightricks/LTX-Video
- Modèle Hugging Face : https://huggingface.co/Lightricks/LTX-2.3
Ce qu’il faut retenir
LTX 2.3 n’est pas un générateur d’images animé.
C’est un modèle vidéo qui doit maintenir la cohérence d’une scène dans le temps. Cette différence change complètement la manière de rédiger un prompt.
Les utilisateurs qui obtiennent les meilleurs résultats appliquent généralement les mêmes principes :
- décrire la physique plutôt que les émotions ;
- privilégier les termes de caméra aux adjectifs artistiques ;
- découper les mouvements complexes ;
- éviter les arrière-plans inutilement chargés ;
- préserver l’identité des personnages avec des images de références ;
- adapter le prompt au workflow utilisé ;
- simplifier autant que possible.
Enfin, gardez à l’esprit qu’une partie des bonnes pratiques présentées dans ce guide provient des mes retours d’expérience et d’observations de la communauté. Les modèles vidéo évoluent rapidement et certaines techniques peuvent gagner ou perdre en efficacité au fil des versions.
Le meilleur moyen de progresser reste donc d’expérimenter, de comparer plusieurs approches et d’ajuster progressivement votre méthode de travail.
Ressources complémentaires
- Documentation officielle LTX : https://docs.ltx.video/
- GitHub officiel LTX : https://github.com/Lightricks/LTX-Video
- Modèle officiel Hugging Face : https://huggingface.co/Lightricks/LTX-2.3
- ComfyUI : https://www.comfy.org/
Pour ne rien rater, abonnez-vous à Cosmo Games sur Google News et suivez-nous sur X (ex Twitter) en particulier pour les bons plans en direct. Vos commentaires enrichissent nos articles, alors n'hésitez pas à réagir ! Un partage sur les réseaux nous aide énormément. Merci pour votre soutien !